
redis 实践
Redis 最佳实践
实践 1
1. 文章访问量统计
博客的一个常见的功能是统计统计文章的访问量,我们可以为每篇文章使用一个名为 post: 文章 ID:page.view 的键来记录文章的访问量,每次访问文章的时候使用 INCR 命令使相应的键值递增。
Redis 对于键的命名并没有强制的要求,但比较好的实践是用”对象类型: 对象 ID: 对象属性”来命名一个键,如使用键 user:1:friends 来存储 ID 为 1 的用户的好友列表,对于多个单词则推荐使用”.”分隔,一方面是沿用以前的习惯(Redis 以前版本的键名不能包含空格等特殊字符),另一方面是在 redis-cli 中容易输入,无需使用双引号包裹,另外为了日后维护方便,键的命名一定要有意义,如 u:1:f 的可读性显然不如 user:1:friends 好(虽然采用较短的名称可以节省存储空间,但由于键值的长度往往远远大于键名的长度,所以这部分节省大部分情况下并不如可读性来得重要)
2. 生成自增 ID
那么怎么为每篇文章生成一个唯一 ID 呢?在关系数据库中我们通过设置字段属性为 AUTO_INCREMENT 来实现每增加一条记录自动为其生成一个唯一的递增 ID 的目的,而在 Redis 中可以通过另一种模式来实现:对于每一类对象使用名为对象类型(复数形式):count 的键(如 users:count)来存储当前类型对象的数量,每增加一个新对象时都使用 INCR 命令递增该键的值。由于使用 INCR 命令建立的键的初始键值是 1,所以可以很容易得知,INCR 命令的返回值既是加入该对象后的当前类型的对象总数,又是该新增对象的 ID。
3. 存储文章数据
由于每个字符串类型键只能存储一个字符串,而一篇博客文章是由标题、正文、作者与发布时间等多个元素构成的。为了存储这些元素,我们需要使用序列化函数(如 PHP 中的 serialize 和 JavaScript 中的 JSON.stringify)将它们转换成一个字符串。除此之外因为字符串类型键可以存储二进制数据,所以也可以使用 MessagePack(MessagePack 和 JSON 一样可以将对象序列化成字符串,但其性能更高,序列化后的结果占用空间更小,序列化后的结果是二进制格式)进行序列化,速度更快,占用空间也更小。
至此我们已经可以写出发布新文章时与 Redis 操作相关的伪代码了:
1 | # 首先获得新文章的 ID |
获取文章数据的伪代码如下(以访问 ID 为 42 的文章为例):
1 | # 从 redis 中读取文章数据 |
实践 2
1. 存储文章数据
之前介绍的存储文章数据的方法是将文章对象序列化后使用一个字符串类型键存储,可是这种方法无法提供对单个字段的原子读写操作支持,从而产生竞态条件,如两个客户端同时获得并反序列化某个文章的数据,然后分别修改不同的属性后存入,显然后存入的数据会覆盖之前的数据,最后只会有一个属性被修改。另外如小白所说,即使只需要文章标题,程序也不得不将包括文章内容在内的所有文章数据取出并反序列化,比较消耗资源。
除此之外,还有一种方法是组合使用多个字符串类型键来存储一篇文章的数据,如图 3-6 所示。
使用这种方法的好处在于无论获取还是修改文章数据,都可以只对某一属性进行操作,十分方便。而本章介绍的散列类型则更适合此场景,使用散列类型的存储结构如图 3-7 所示。
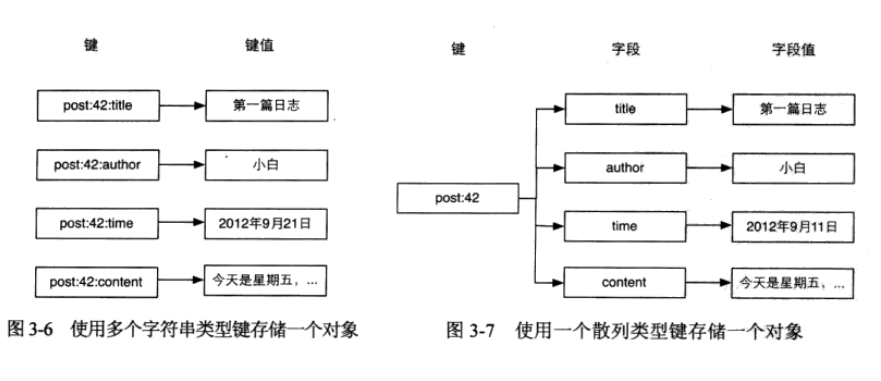
从图 3-7 可以看出使用散列类型存储文章数据比图 3-6 所示的方法看起来更加直观也更容易维护(比如可以使用 HGETALL 命令获得一个对象所有字段,删除一个对象时只需要删除一个键),另外存储同样的数据散列类型往往比字符串类型更加节省空间。
2. 存储文章缩略名
使用过 WordPress 的读者可能会知道发布文章时一般需要指定一个缩略名(slug)来构成该篇文章的网址的一部分,缩略名必须符合网址规范且最好可以与文章标题含义相似,如”This Is A Great Post!”的缩略名可以为”this-is-a-great-post”。每个文章的缩略名必须是唯一的,所以在发布文章时程序需要验证用户输入的缩略名是否存在,同时也需要通过缩略名获得文章的 ID。
我们可以使用一个散列类型的键 slug.to.id 来存储文章缩略名和 ID 之间的映射关系。其中字段用来记录缩略名,字段值用来记录缩略名对应的 ID。这样就可以使用 HEXISTS 命令来判断缩略名是否存在,使用 HGET 命令来获得缩略名对应的文章 ID 了。
现在发布文章可以修改成如下代码:
1 | $postID=INCR posts:count |
这段代码使用了 HSETNX 命令原子地实现了 HEXISTS 和 HSET 两个命令以避免竞态条件。当用户访问文章时,我们从网址中得到文章的缩略名,并查询 slug.to.id 键来获取文章 ID:
1 | $postID=HGET slug.to.id, $slug |
需要注意的是如果要修改文章的缩略名一定不能忘了修改 slug.to.id 键对应的字段。如果修改 ID 为 42 的文章的缩略名为 newSlug 变量的值:
1 | # 判断新的 slug 是否可用,如果可用则记录 |